data 저장 원리
2진수를 16진수로 변환하기
| 진수 | 숫자 |
|---|---|
| 2진수 | 10100111 |
| 10진수 | 10 7 |
| 16진수 | 0X A 7 |
메모리는 byte들의 연속적인 배열
data -> 2진수 변환 규칙
정수
1. sign-magnitude
- 양수와 음수는 부호만 다르고 값은 같다.
- 부동소수점의 가수부를 표현할 때 사용
- 1byte중 2진수의 첫자리 숫자는 부호비트 (+ = 0, - = 1)
+24 -> 00011000
-24 -> 10011000
단점
- (-) 연산 결과가 일반적이지 않다.
- 첫자리가 부호비트이므로 +0과 -0이 존재
2. one’s complement
- 음수는 양수에 대한 1의 보수이다.
0또는 1에 대한 1의 보수
0 + 1 = 1 -> 1
1 + 0 = 1 -> 0
9의 보수
8 + 1 = 9 -> 1
7 + 2 = 9 -> 2
+24 -> 00011000
-24 -> 11100111
단점
- (-) 연산 결과가 1 부족하다.
- 첫자리가 부호비트이므로 +0과 -0이 존재
3. two’s complement
- 음수는 양수에 대한 2의 보수이다.
- 2의 보수 = 1의 보수 + 1
+24 -> 00011000
-24 -> 11101000 = 11100111 + 1
- 현대 컴퓨터는 음수를 표현할 때 2의 보수를 사용
4. excess-k (k 초과)
- 부동소수점의 지수부 (exponent)를 표현할 때 사용
k값 = bias 값 = 편중된 값
bias 값 계산 공식
k = 2^(메모리 비트 수 - 1) -1
ex) 8bit -> 2^(8-1) - 1 = 127 = k
32bit -> 2^(32-1) - 1 = 2147483647 = k
정수 + k값 = 2진수
128 + 127 = 255 -> 11111111
2 + 127 = 129 -> 10000001
1 + 127 = 128 -> 10000000
0 + 127 = 127 -> 01111111
-1 + 127 = 126 -> 01111110
-2 + 127 = 125 -> 01111101
-127 + 127 = 0 -> 00000000
문자
1. ASCII
- 알파벳 대/소문자, 숫자, 특수문자
- 7bit 사용
A -> 1000001 = 0x41
B -> 1000010 = 0x42
C -> 1000011 = 0x43
a -> 1100001 = 0x61
b -> 1100010 = 0x62
c -> 1100011 = 0x63
0 -> 0110000 = 0x30
1 -> 0110001 = 0x31
2 -> 0110011 = 0x32
0000000 ~ 1111111 총 128의 수
95자에 대해 7bit 2진수 규칙을 정함
- 국제 표준 아님
2. ISO-8859-1~16 (ISO-latin-1)
-
ASCII + 유럽 문자 외 세계 문자
-
8bit 사용
-
표현되지 않는 문자가 많음
-
한글 windows 기본 문자표
-
한글은 2byte로 표현해야 함
-
국제 표준
3. EUC-KR
-
ISO-8859-1 + 한글
-
16bit로 한글 문자 정의
가 -> 1011 0000 1010 0001 -> 0xB0A1
각 -> 0xB0A2
간 -> 0xB0A3
똘 -> 0xB6CA
똠 -> 정의없음 -> 또ㅁ 출력
똡 -> 정의없음 -> 또ㅂ 출력
똣 -> 정의없음 -> 또ㅅ 출력
똥 -> 0xB6CB
- 국제 표준
4. 조합형
- 2byte = 1bit (영 = 0, 한 = 1) + 5bit (초성) + 5bit (중성) +5bit (종성)
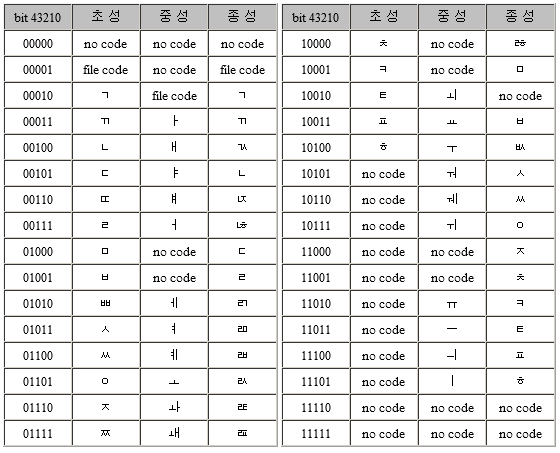
초성 5bit
ㄱ -> 00010
ㄲ -> 00011
ㄴ -> 00100
ㄷ -> 00101
중성 5bit
ㅏ -> 00011
ㅐ -> 00100
ㅑ -> 00101
ㅒ -> 00110
ㅓ -> 00111
ㅔ -> 01010
종성 5bit
ㄱ -> 00010
ㄲ -> 00011
ㄳ -> 00100
ㄴ -> 00101
ㄵ -> 00110
걘 -> 1 00010 00110 00101 -> 0x88C5
- 국제 표준 아님
5. MS-949 (CP949)
-
EUC-KR + … = 11172자
-
16bit 사용
똘 -> B6CA
똠 -> 8C63
똡 -> 8C64
똣 -> 8C66
똥 -> B6CB <= character code
- 한글 windows OS의 기본 characterset
characterset (문자집합) : 문자에 대해 2진수를 매핑한 규칙
character code : 문자에 대해 정의된 2진수 (16진수)
- 국제 표준 아님
6. UNICODE
- 2byte
- UNICODE4 : 4byte
- 모든 문자를 2byte로 정의
A -> 0041
1 -> 0031
가 -> AC00
각 -> AC01
똘 -> B618
똠 -> B620
똡 -> B621
똣 -> B623
똥 -> B625
- 영문자도 2byte이므로 메모리 낭비
- 기존 편집기 사용 불가
- 한글은 EUC-KR과 호환되지 않아 모든 문자를 새 값으로 재정의
- 한글의 모든 문자 코드가 정렬됨
- 국제 표준
7. UTF-8
- 기존의 편집기에서도 영어를 읽고 쓸 수 있도록 제작
- 7bit로 정의해서 쓰던 문자는 그대로 7bit 사용 ex) ASCII
- 그 외 문자는 규칙에 따라 2~4byte로 변환 ex) 한글 : 2byte -> 3byte 변환 (메모리차지 커짐)
가 -> UNICODE2 (UTF-16 = UCS2) : AC00 -> 1010 1100 0000 0000
가 -> UTF-8 (Universal Coded Character Set + Transformation Format : UNICODE 변형 방식) : 1010 1100 0000 0000 -> 1110<u>1010</u> 10<u>10000</u> 10<u>000000</u> -> EAB080
색상
| 색상 | bit수 | 빛의 세기 |
|---|---|---|
| RED | 8bit | 00~ff |
| GREEN | 8bit | 00~ff |
| BLUE | 8bit | 00~ff |
| 색상 | R | G | B |
|---|---|---|---|
| red | FF | 00 | 00 |
| green | 00 | FF | 00 |
| yellow | FF | FF | 00 |